llama.cpp运行本地模型
在编译安装好 llama.cpp 与下载完成模型文件到本地后,就可以运行本地模型进行推理。下面将简单介绍如何使用 llama.cpp 加载运行推理模型。
命令行运行
llama.cpp 提供了 CLI 工具给用户在命令行中直接使用,例如使用如下的命令运行:
shell
llama-cli -m /share/apps/models/Qwen2.5-1.5B-Instruct-GGUF/qwen2.5-1.5b-instruct-q8_0.gguf -n 512 -co -sp -cnv -p "Who are you?"llama-cli -m /share/apps/models/Qwen2.5-1.5B-Instruct-GGUF/qwen2.5-1.5b-instruct-q8_0.gguf -n 512 -co -sp -cnv -p "Who are you?"以服务运行
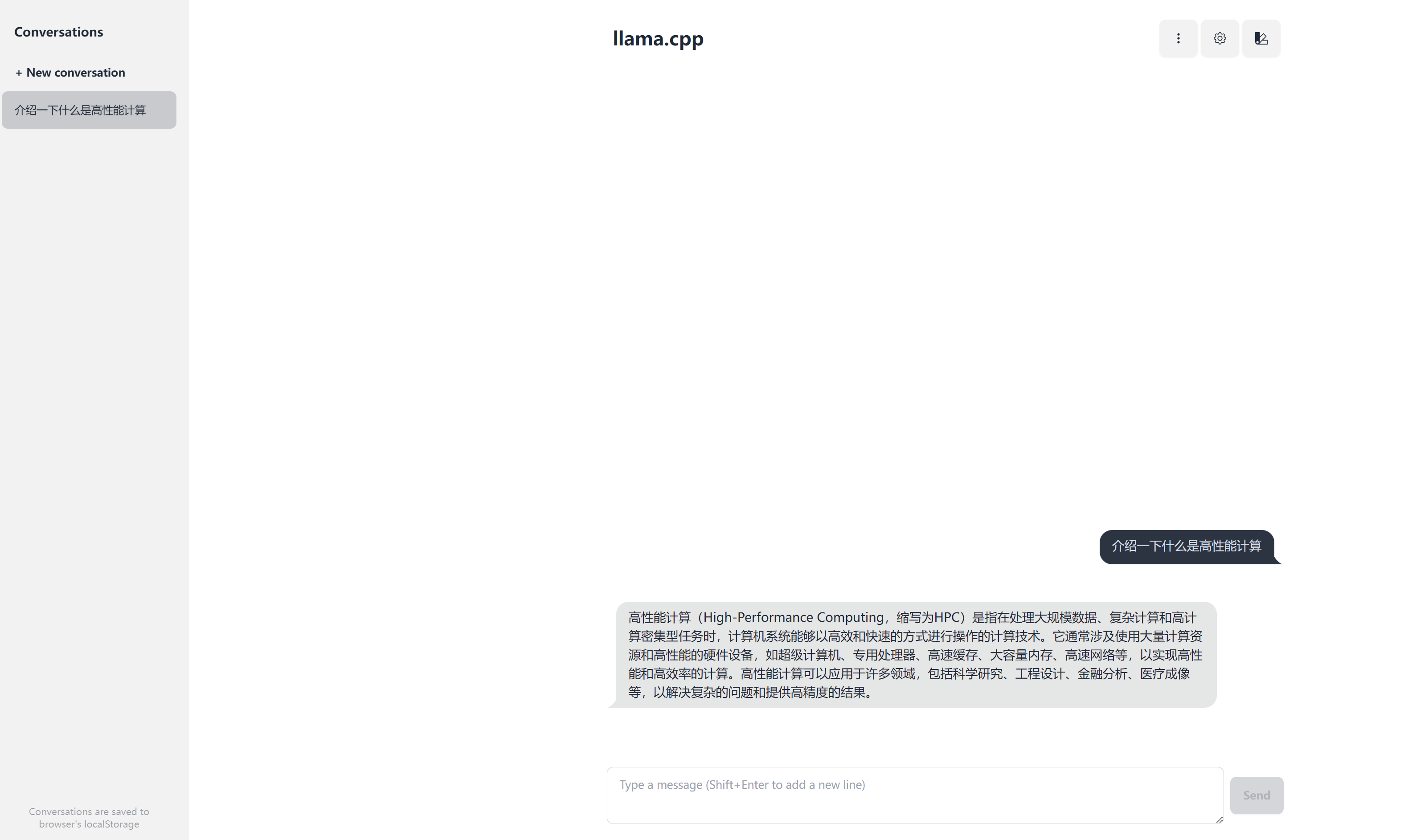
llama.cpp也提供简单的服务端运行,直接执行如下的命令:
shell
llama-server -m /share/apps/models/Qwen2.5-1.5B-Instruct-GGUF/qwen2.5-1.5b-instruct-q8_0.gguf --host 0.0.0.0 --port 8080llama-server -m /share/apps/models/Qwen2.5-1.5B-Instruct-GGUF/qwen2.5-1.5b-instruct-q8_0.gguf --host 0.0.0.0 --port 8080用户可以通过对应的 http://IP:8080 网址来访问服务器,可以看到如下的官方内置的简易网页交互界面: